LLM 学习笔记
大型语言模型(llm)是一种特殊的预训练语言模型,通过调整模型大小、预训练语料库和计算来获得。由于llm规模大,对大量文本数据进行预训练,表现出特殊的能力,能够在许多自然语言处理任务中不经过任何特定任务训练的情况下取得显著的性能。
llm的时代始于OpenAI的GPT-3模型,在ChatGPT和GPT4等模型的引入后,llm的流行程度呈指数级增长。
LLM 表现出根据相对较少量的提示或输入做出预测的非凡能力。LLM 可用于生成式人工智能,以根据采用人类语言的输入提示生成内容。
基于transformer架构的LLM:
自注意力机制,关注词和当前输入序列的所有词的关系,提高训练速度

文本token化
每个被一个整数表示
传入嵌入层,每个token被一个向量表示(词向量),向量空间中可以表示更多相关性(多维度)
位置编码
代表词位置的位置向量与词向量组合,使模型同时理解词的意义以及在句中的关系
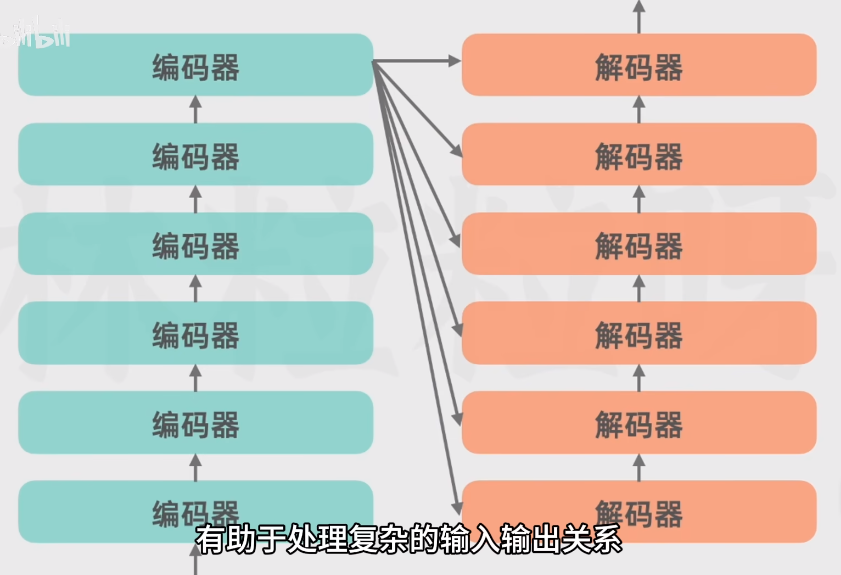
编码器(多级串联->更深入了解)
多头自注意力机制-> 词之间相关性表示权重
有多头自注意力机制,用来关注文本不同特征方面(动词、名词),并行运算互不影响,每个头的权重是训练中调整的。
位置编码的向量传入,加入自注意力机制的权重表示,输出(三种信息融合在向量里)向量。(同一个词,上下文不同表示不同)
前馈神经网络,增加模型表达能力
解码器(生成)
一个特殊值(便于考虑之前已经生成的上文保持上下文连贯性)已生成的输出序列经过另一编码器,但使用 带掩码的多头自注意力机制,即自注意力头只关注当前词和其之前的词的关系权重,
确保解码器生成文本遵循正确时间顺序
编码器传出的向量(token的抽象表示)->多头自注意力
用来捕捉解码器即将产生成的输出以及编码器输入之间的关系,使输入序列信息融合到解码器输出中
前馈神经网络,增加模型表达能力
线性层,softmax层,转换解码器输出到词汇表概率分布(实现猜下一个词)
扩展
仅解码器:掩码语言建模、情感分析 BERT
仅解码器:猜测上下文文本生成 GPT2、3
解码器解码器模型/ 序列到序列模型:翻译总结 T5、bart